

文本生成圖片和圖片生成圖片已經逐漸取代繪畫師和設計師了,你有沒有想過有一天文字和圖片還可以生成3D模型?科技的發展只有我們想不到,沒有AI做不到。那么對3d模型領域又會有哪些影響呢?手把手硬核AI教學,趕快收藏學習。
一、文本生成3d模型
在text to 3d(文本生成3d)和image to 3d(圖片生成3d)方向比較成熟應用的有自動生成3D模型的AI應用,例如如下這個網站,可以根據圖片和文字生成180度的2.5D模型

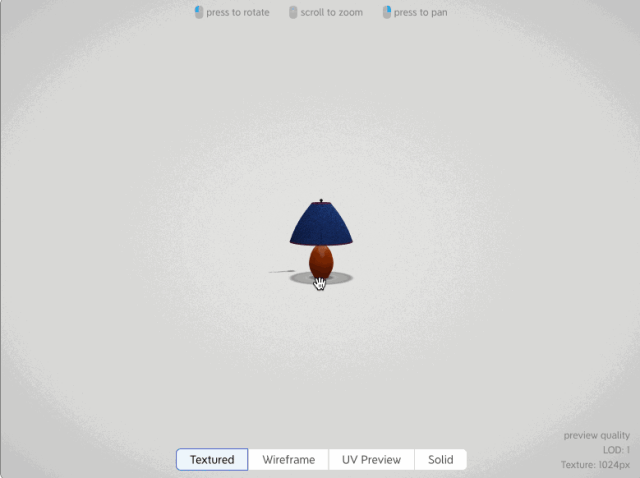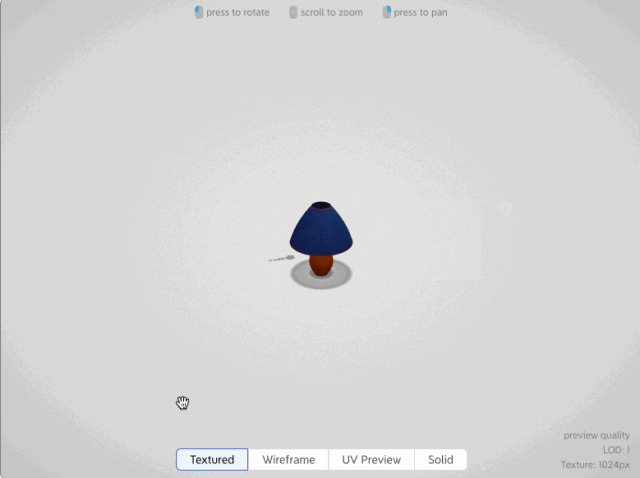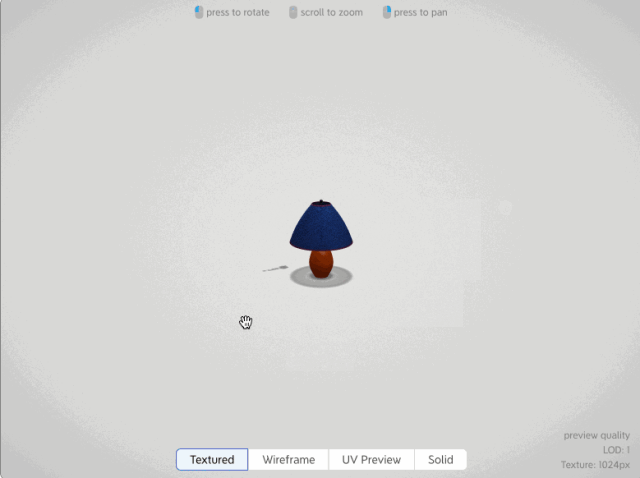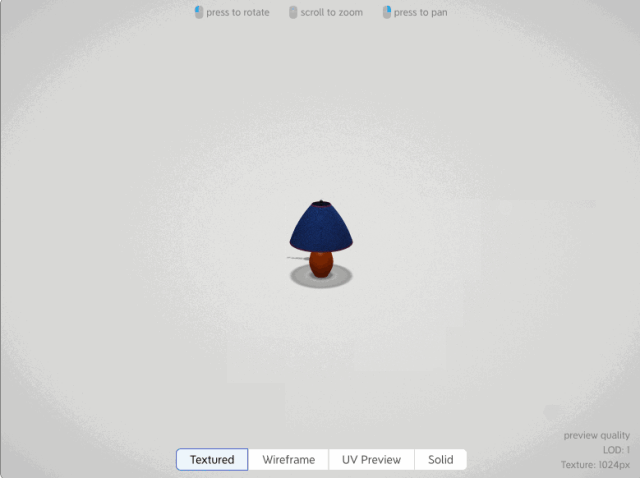
而真正目前text to 3d比較成熟的開源框架是OpenAI發布的shap-e開源模型,不僅能根據文本和圖片來生成3d動畫效果,而且還可以把生成的3d模型導出到3d編輯軟件里進行編輯。
OpenAI Shap-e手把手硬核步驟教學
一、Shap-e介紹
github項目地址:
https://github.com/openai/shap-e

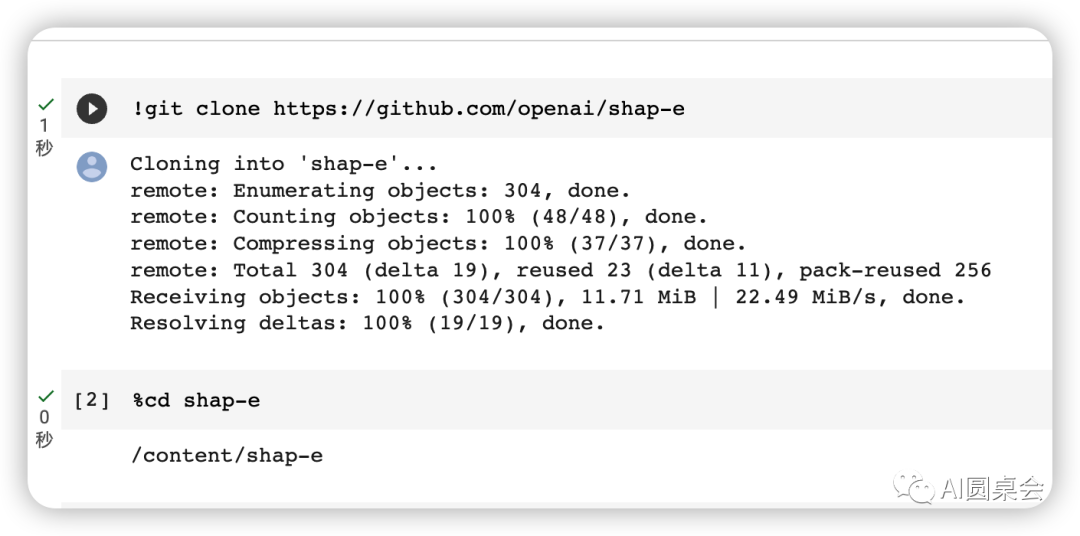
二、colab上部署Shap-e 復制并打開自動執行腳本:
https://colab.research.google.com/drive/1XvXBALiOwAT5-OaAD7AygqBXFqTijrVf?usp=sharing#scrollTo=7-fLWame0qJw按執行步驟一步步執行
三、參數修改
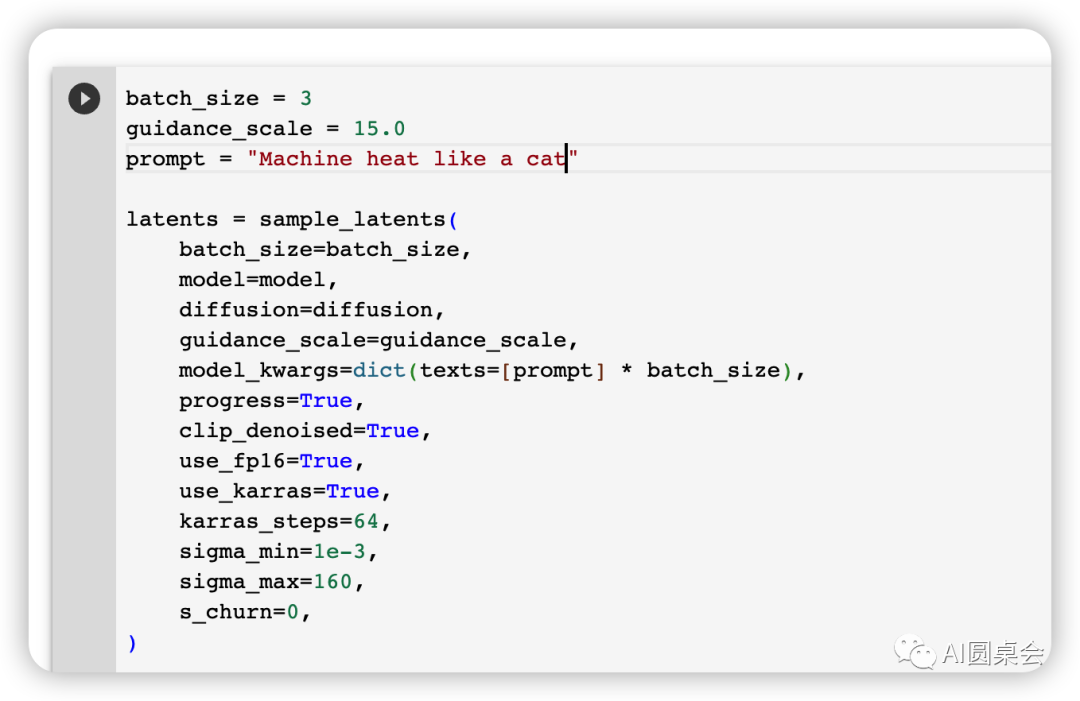
batch_size = 生成的數量
guidance_scale = 分辨率
prompt = 生成內容指令
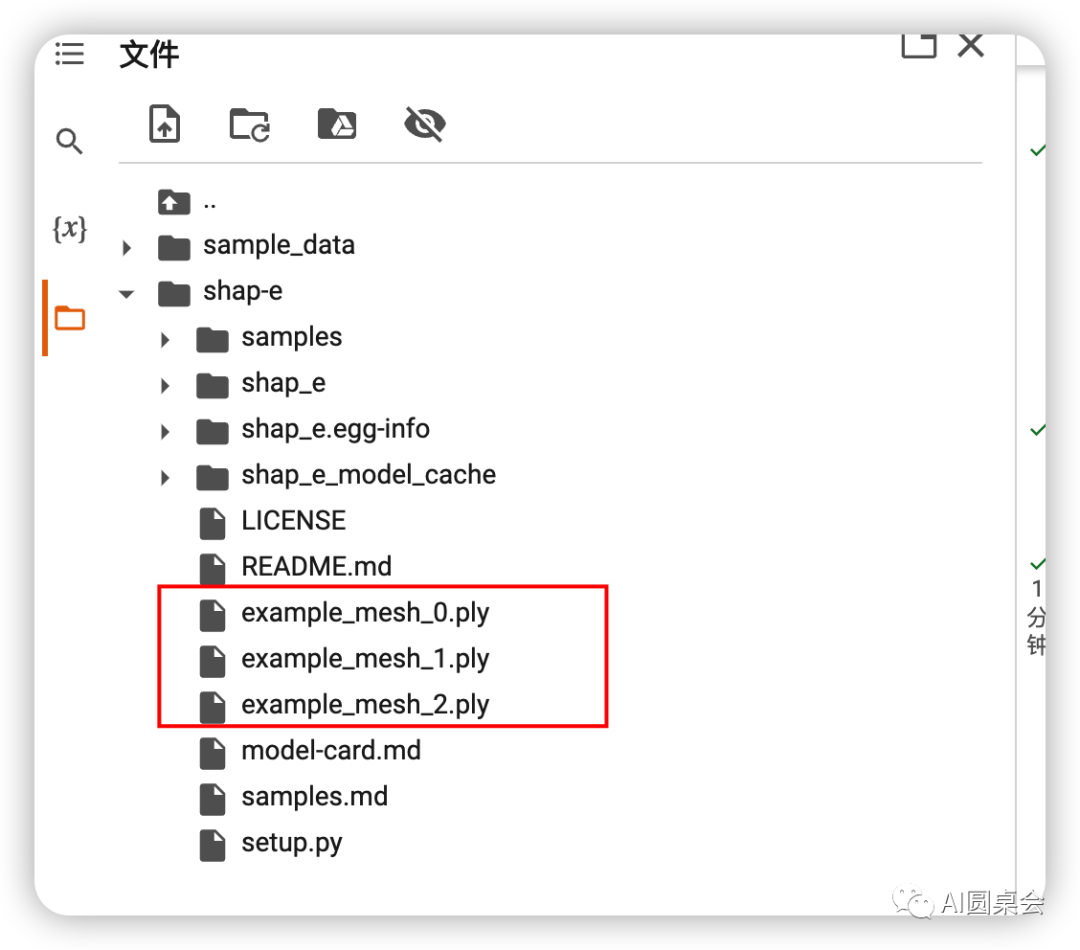
四、文件下載并使用編輯器進行編輯使用
在左側文件夾里找到生成的文件并下載使用3d編輯器即可對模型進行修改編輯
OpenAI發布的shap-e開源模型。
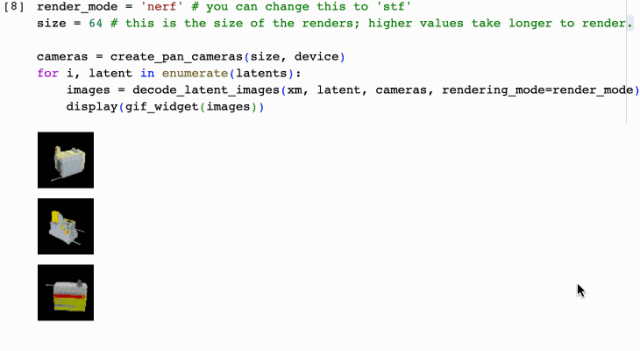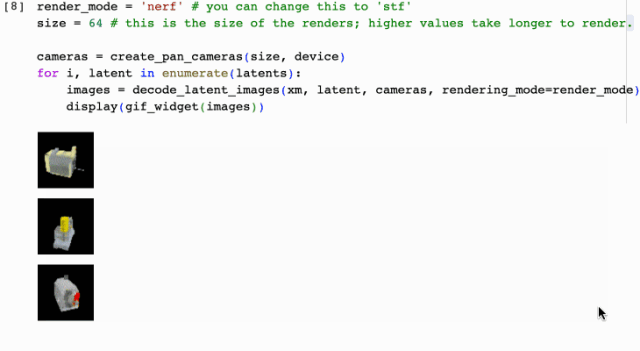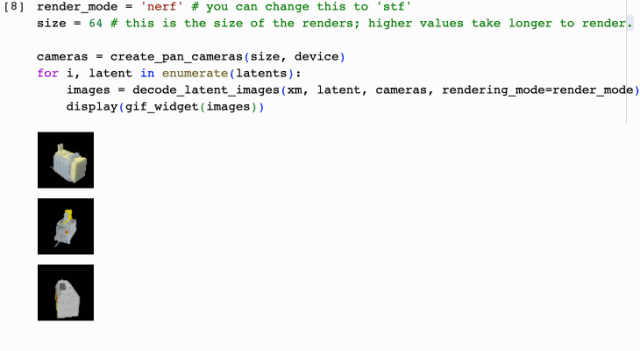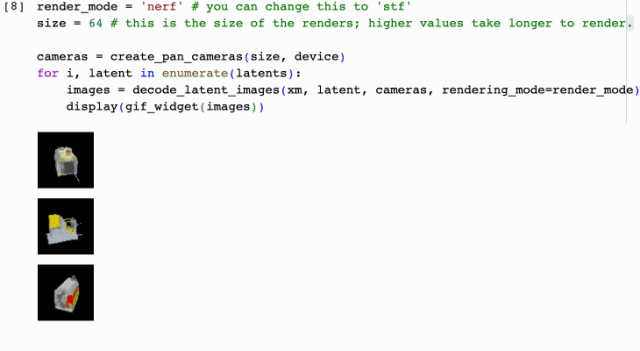

這就結束了?更炸裂的來了,接下來手把手演示如果通過圖片提示來生成3D動畫效果,上車出發
二、圖片生成3d模型

請直接復制
import torchfrom shap_e.diffusion.sample import sample_latentsfrom shap_e.diffusion.gaussian_diffusion import diffusion_from_configfrom shap_e.models.download import load_model, load_configfrom shap_e.util.notebooks import create_pan_cameras, decode_latent_images, gif_widgetfrom shap_e.util.image_util import load_image
接下來找到第六步更改模型,替換圖片解析模型
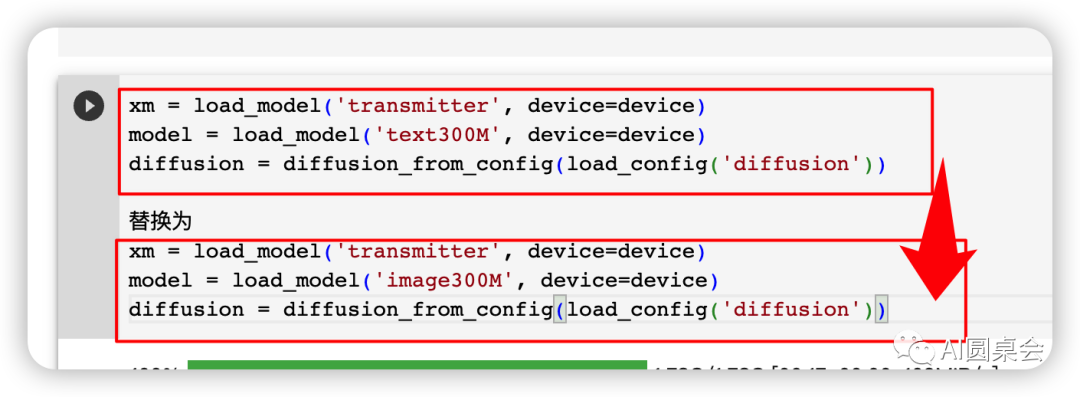
無腦復制代碼
xm = load_model('transmitter', device=device)model = load_model('image300M', device=device)diffusion = diffusion_from_config(load_config('diffusion'))
別急,快看到終點了
準備一張圖片上傳到content文件夾里,圖片格式.png .jpg
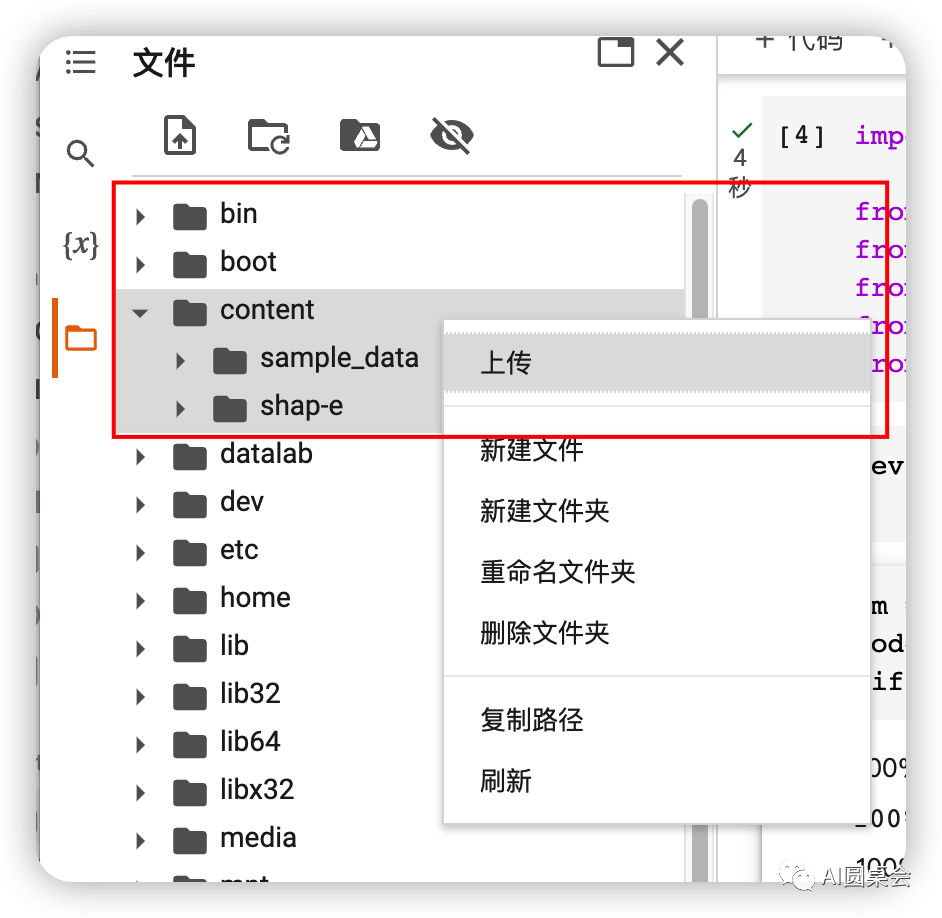
粘貼第四段代碼到標注處
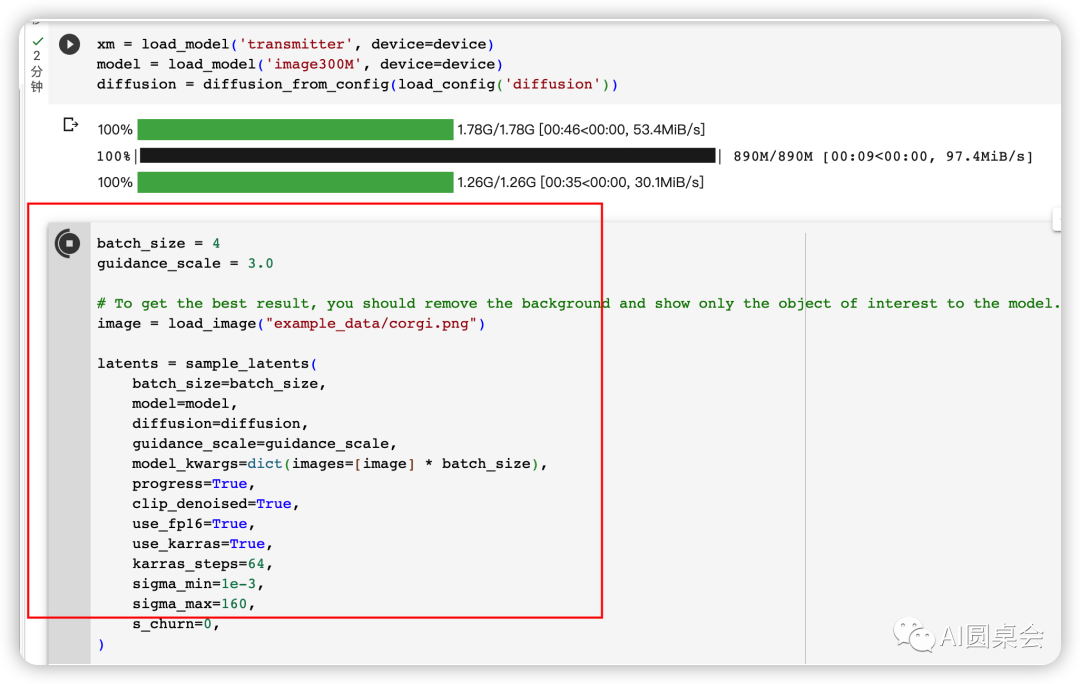
繼續無腦復制如下代碼
batch_size = 4guidance_scale = 3.0# To get the best result, you should remove the background and show only the object of interest to the model.image = load_image("example_data/corgi.png")latents = sample_latents(batch_size=batch_size,model=model,diffusion=diffusion,guidance_scale=guidance_scale,model_kwargs=dict(images=[image] * batch_size),progress=True,clip_denoised=True,use_fp16=True,use_karras=True,karras_steps=64,sigma_min=1e-3,sigma_max=160,s_churn=0,)
修改參數
batch_size = 生成的數量guidance_scale = 分辨率img = 圖片保存路徑
別走,最后一步老鐵
復制如下代碼到最后一步render_mode = 'nerf' # you can change this to 'stf' for mesh renderingsize = 64 # this is the size of the renders; higher values take longer to render.cameras = create_pan_cameras(size, device)for i, latent in enumerate(latents):images = decode_latent_images(xm, latent, cameras, rendering_mode=render_mode)display(gif_widget(images))
別憂慮點擊執行,就會得到image to 3d模型了,照常按著以上步驟去編輯吧

just do it!






